Scraping TripAdvisor : Getting past usual web scraping problems
- Dec 23, 2022
- 3 min read
A recent client had asked me to scrape through a few real estate websites and during the process I had come across many problems that I would face during web-scraping.
Although I can not show you the real-estate data, since it is sensitive information, here is a simple way to web scrape any website and the ways to tackle the problems during it. I have taken tripadvisor.in since they allow people to scrape their site.
The final data looks something like this:
Importing the libraries
We import the two most important libraries to scrape our site.
import requests
from bs4 import BeautifulSoup as soupWe use 'requests' library to make a HTTP request that is to access resources from the host's server and Beautiful Soup is a Python package for parsing HTML and XML documents I t is used to extract data from HTML.
Storing the URL of the website
We store the URL of the website in a variable so that we can scrape it. We store it as:
url='https://www.tripadvisor.in/'# Problem 1 : Website identifies you as a "BOT"
To prevent the website identifying you as a bot, just use the following command:
headers={Mozilla/5.0 (<system-information>) <platform> (<platform-details>) <extensions>}Everybody has different user agents and they can find their respective user agent through their browser or use this site: https://gs.statcounter.com/detect
Sending the request to the website
We use the below command to request the site to access their resource which is in the form of a HTML document.
response=requests.get(url,headers=headers)After requesting, we parse the information from the HTMl documents using 'soup'.
jim=soup(response.content,'html.parser')'Jim' is just a random variable that I am using to store my information. You can call it whatever you want to.
#Problem 2 : Finding the right containers
Containers are where the information is stored. Each containers consists of class and division. The HTML class attribute specifies one or more class names for an element. Classes are used by CSS and JavaScript to select and access specific elements. The <div> tag defines a division or a section in an HTML document.
Now, the we have to find the right class and division so that we can extract a particular data. The best practice is to hover your cursor on top of the element you want to inspect and keep opening the divisions until you find the specific class.
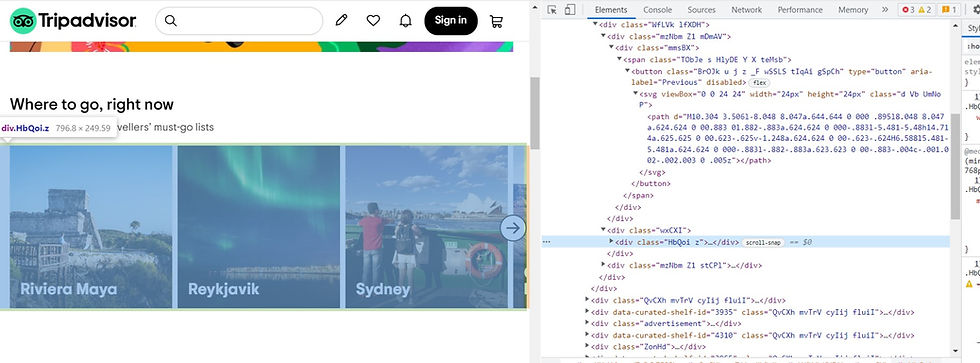
As you can see, I have opened several divisions until I reach the right tag.
Remember to not open it completely until there is only one specific information left. You have to find the general class name and division that has the information to all the values in the site and not one specific value.
We store that division into a variable.
containers=jim.find_all('div',{'class':'HbQoi z'})Looking for the exact information within the container
Now, we extract the information we need from the container variable. Here, I want to know the Name of the area and the number of rentals available in that area.
for i in containers:
name=i.find_all('div',{'class':'biGQs _P fiohW alXOW NwcxK GzNcM ytVPx UTQMg RnEEZ ngXxk'})
rentals=i.find_all('div',{'class':'biGQs _P fiohW fOtGX'})
Extracting texts from the values:
name = [i.get_text() for i in name]
rentals = [i.get_text() for i in rentals]Converting the arrays of information into a dataset:
We convert the two lists into a dataframe.
import pandas as pd
#Transposing since data is arranged horizontally by default
df=pd.DataFrame([name,rentals]).transpose()
#Renaming columns
df.columns=['Name','Rentals']Finally we get the data into this format:

Exporting it as an Excel File
We use the following command to convert the data from our python compiler to an excel file:
df.to_excel('rentals.xlsx')



Comments